Los nuevos tiempos están marcados por el signo de la era digital, la globalización y la ingente cantidad de datos generados a diario, el Big Data que viene aparejado a grandes desafíos y no menores oportunidades.
Más allá de las famosas 5 Vs que lo caracterizan (velocidad, volumen, variedad, veracidad y valor), Big Data significa, sobre todo, grandes posibilidades en los campos más inimaginables. Y lo hace, sobre todo, porque contamos con nuevas tecnologías surgidas para responder con una eficiencia inédita a las necesidades de almacenamiento y análisis de los grandes datos.
Son muchas las tecnologías y conceptos que forman parte de este universo de los grandes datos, cuyo crecimiento es imparable, como el Internet de las cosas (IoT), el intercambio de datos máquina a máquina (M2M), el cada vez más complejo entorno de TI o el predictivo machine learning.
La importancia de procesar los datos
Los desafíos que lanza Big Data, en efecto, precisan de enfoques y sistemas capaces de recabar, almacenar, realizar búsquedas eficientes y, en fin, llevar a cabo análisis cuyos resultados puedan ser convenientemente visualizados.
Pero los desafíos vienen acompañados de todo un mundo de oportunidades para muy diferentes actores, a nivel científico, empresarial o en lo que respecta a las organizaciones públicas.
La revolución del conocimiento ha llegado y el objetivo es claro: valorizar los datos para explotarlos, un punto clave en el que además de innovadoras tecnologías entra en juego el data science y la figura del data scientist.
Se trata, en suma, de aplicar tecnologías creando estrategias y metodologías ad hoc para aplicar complejos algoritmos que nos proporcionen una información privilegiada de cara a una mejor toma de decisiones.
No en vano, los datos sirven de bien poco si no implementamos soluciones a la medida. Sin un propósito y tecnología capaz de gestionarla el valor de los datos será nulo. Por contra, procesar esa información en la dirección buscada permite un buen manejo de los datos para la obtención de ventajas comparativas.
El mismo hallazgo de la información buscada es en sí mismo un gran éxito, la llave que nos permitirá avanzar en nuestro objetivo. Por lo tanto, los datos no son un fin en sí mismos sino un medio para llegar a esa información realmente valiosa que haga la diferencia.
Los objetivos pueden ser de muy distintos tipos, desde monetizar la información hasta convertirla en una eficaz herramienta para mejorar la gobernabilidad, tal y como ocurre en los proyectos de las ciudades inteligentes.
Machine learning, inteligencia artificial predictiva
Dentro de este complejo pero al mismo tiempo apasionante contexto, la tan de moda parte de la inteligencia artificial dedicada al aprendizaje por parte de las máquinas, el machine learning trata de que los sistemas aprendan automáticamente.
Entendemos esa acción de aprendizaje como la identificación de patrones complejos en millones de datos. Básicamente, la máquina es capaz de predecir comportamientos “aprendiendo” un algoritmo que revisa los datos.
La peculiaridad de sus métodos de predicción, basados en métodos algorítmicos donde la certeza del modelo teórico, deja paso a modelos aproximados basados en la probabilidad y la estadística. Esta forma de modelar la realidad, en base a probabilidades, es la que nuestro cerebro sigue, apoyado por su gran capacidad de cómputo. La certeza absoluta no existe para nuestro cerebro, cada uno de nosotros interpreta la realidad y la ajusta según una determinada probabilidad, la necesaria en el momento
Libre de la certeza absoluta del modelo, tal como se describe previamente, su nivel de fiabilidad se moverá dentro de una determinada horquilla, considerada con un nivel de eficacia significativo. A tal efecto, será decisiva la utilidad práctica que pueda brindar un determinado porcentaje de aciertos.
Y los resultados pueden llegar a ser espectaculares, tal y como demuestran dos de sus mayores logros: el reconocimiento de voz de Google o el facial de Facebook. En ambos casos, sin llegar al modelo real que subyace a cada uno, aplicando algoritmos de machine learning y obteniendo modelos aproximados con un margen de error aceptable y con una velocidad de cómputo enorme. Es esta velocidad de cómputo lo perseguido en la mayoría de los casos, buscando un error muy pequeño en la predicción en un tiempo de cómputo aceptable a la aplicación.
Aplicaciones del machine learning
Los campos de aplicación del machine learning son innumerables. Sectores como el e-commerce y el marketing en general son solo una pequeñísima muestra de lo mucho que puede ofrecer un proyecto de machine learning.
A la hora de plantear cualquier iniciativa, la imaginación puede jugar un gran papel, sin más límites que la legalidad y la ética. El campo de aplicación, en suma, depende del margen, del presupuesto y de los datos que estén disponibles.
Los equipos de data science que se plantean encontrar la famosa aguja en el pajar encuentran en el machine learning un gran aliado. Si bien existen planteamientos híbridos, son sistemas que auto aprenden dentro de un océano de datos, sin necesidad de otra programación.
Machine learning, por ejemplo, es el corazón de los sistemas de recomendaciones de gigantes de la red como eBay, Amazon, Twitter, Facebook o LinkedIn, así como de un sinfín de proyectos de detección de fraude en redes de comunicaciones de datos, de reconocimiento de voz, averías en máquinas, fallos en equipos tecnológicos, algoritmos para predecir enfermedades, clientes potenciales, delitos o tendencias de consumo.
Aplicaciones de machine learning en Smart City
A nivel de la smart city, cualquiera de los avances logrados en este campo puede tener aplicaciones muy interesantes. Desde el reconocimiento facial o de voz para llevar a cabo programas de inclusión social de personas discapacitadas hasta, pongamos por caso, flexibilizar el comportamiento de una aplicación móvil para adaptarse a las preferencias y necesidades de cada usuario.
Predecir el tráfico urbano o hacer pre-diagnósticos médicos en función de los síntomas del paciente son otros ejemplos de proyectos enmarcados en el entorno de la smart city que pueden surgir aprovechando el gran potencial de datos anónimos.
Lejos de resultar inservibles, en realidad pueden aportar mucho valor, como se demuestra en los siguientes tres ejemplos que desarrollamos a continuación, centrados en la mejora de la salud pública, la movilidad sostenible y la seguridad en las ciudades.
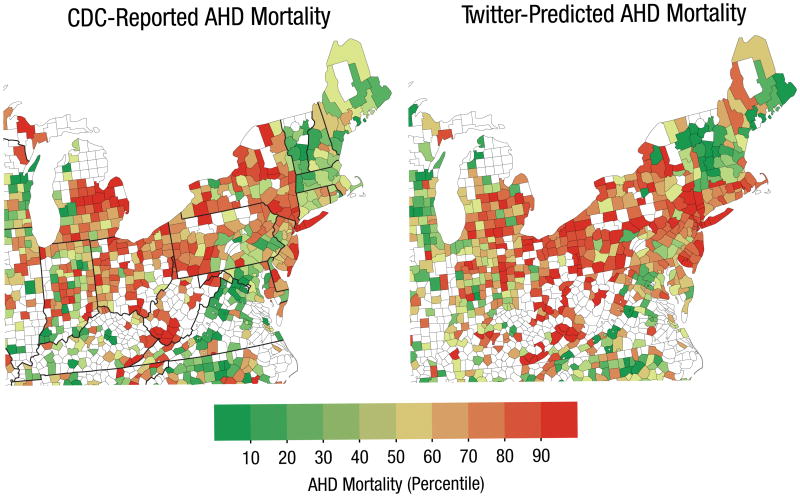
En primer lugar, psicólogos estadounidenses hallaron información de gran utilidad para mejorar las políticas de prevención sanitaria. En esta ocasión lo lograron analizando el tono optimista o pesimista de los tuits en distintas áreas geográficas y estableciendo una correlación con las tasas de muertes por problemas cardíacos.
Al superponer el mapa generado por los tuits sobre el mapa que señalaba los datos de mortalidad por patologías coronarias encontraron sorprendentes similitudes. Gracias al análisis de 148 millones de tuits de 1347 condados de Estados Unidos predecir las tasas de enfermedades del corazón con mayor eficacia que los tradicionales factores de riesgo, entre otros la obesidad, la diabetes o el tabaquismo.
La conclusión del estudio, llevado a cabo por científicos de la Universidad de Pensilvania no ofrece lugar a dudas: el ambiente sociogeográfico influye de forma decisiva en los problemas coronarios. En definitiva, un análisis eficaz a nivel social que no puede aplicarse a individuos particulares, pero sí resulta de gran relevancia para aplicar medidas políticas ad hoc. E incluso para hacer un seguimiento de los resultados, una vez aplicadas las campañas.
En el diseño de las smart cities, por otra parte, la movilidad sostenible es uno de los grandes objetivos. A este respecto, la Workshop Internacional IEEE sobre Movilidad Urbana y Sistemas de Transporte Inteligente UMITS 2016 fue un evento de referencia en el que se presentaron iniciativas de vanguardia en favor de la movilidad urbana y sistemas de transporte inteligente.
En el evento se presentó el trabajo “Understanding Daily Mobility Patterns in Urban Road Networks using Traffic Flow Analytics“, elaborado por Tecnalia dentro del proyecto una plataforma cloud con servicios y herramientas de movilidad inteligente en el contexto de las ciudades inteligentes.
Uno de los puntos fuertes del proyecto, precisamente, reside en el desarrollo de algoritmos de predicción de distintas variables de tráfico (intensidad de vehículos en una vía o su nivel de ocupación) alimentados por datos en real time de la ciudad de Madrid.
Según apuntan sus creadores, fue mediante la aplicación de técnicas de machine learning para el estudio de diferentes cuestiones que afectan al tráfico como se logró mejorar la eficacia de las predicciones.

Por último, un trabajo conjunto de la Fondazione Bruno Kessler (FBK), el MIT y Telefónica I+D constituye uno de los principales logros del machine learning para prever riesgos sociales a partir del análisis del comportamiento humano.
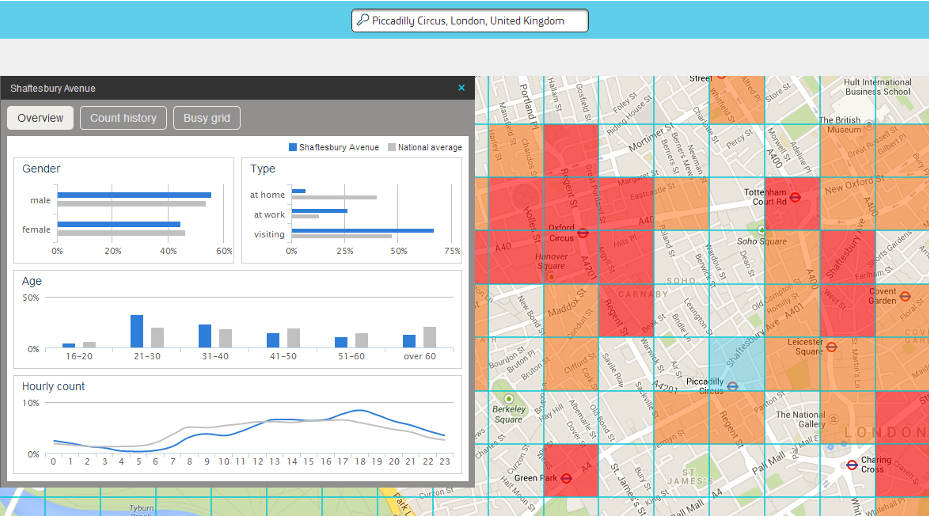
En este caso, relacionados con la delincuencia. Su proyecto, “Crime Hot Spots”, es un minado de datos generados por los smartphones, que permite detectar futuras escenas de crimen. En concreto, puede predecir en qué distrito es más probable que ocurra un crimen en la ciudad de Londres con una precisión de alrededor del 70 por ciento.
Frente a los sistemas convencionales, representa un enorme avance. En lugar de basarse en la costosa y lenta recogida de datos de estadísticas criminales y demografía local recurre a un logaritmo confeccionado a partir de fuentes estadísticas criminales y demográficas de la City, junto con datos que emiten los teléfonos móviles para recoger información clave sobre sus dueños, como su geolocalización en real time, así como el sexo y la edad.
Tras una fase de refinado del sistema que garantice el anonimato de los datos y se busquen adaptaciones a otros entornos culturales, se pretende brindar como información para su uso público. Sus creadores no andan nada errados cuando afirman que sus resultados podrían ser de mucho interés para gobiernos y fuerzas de seguridad.